General challenges in spatiotemporal prediction
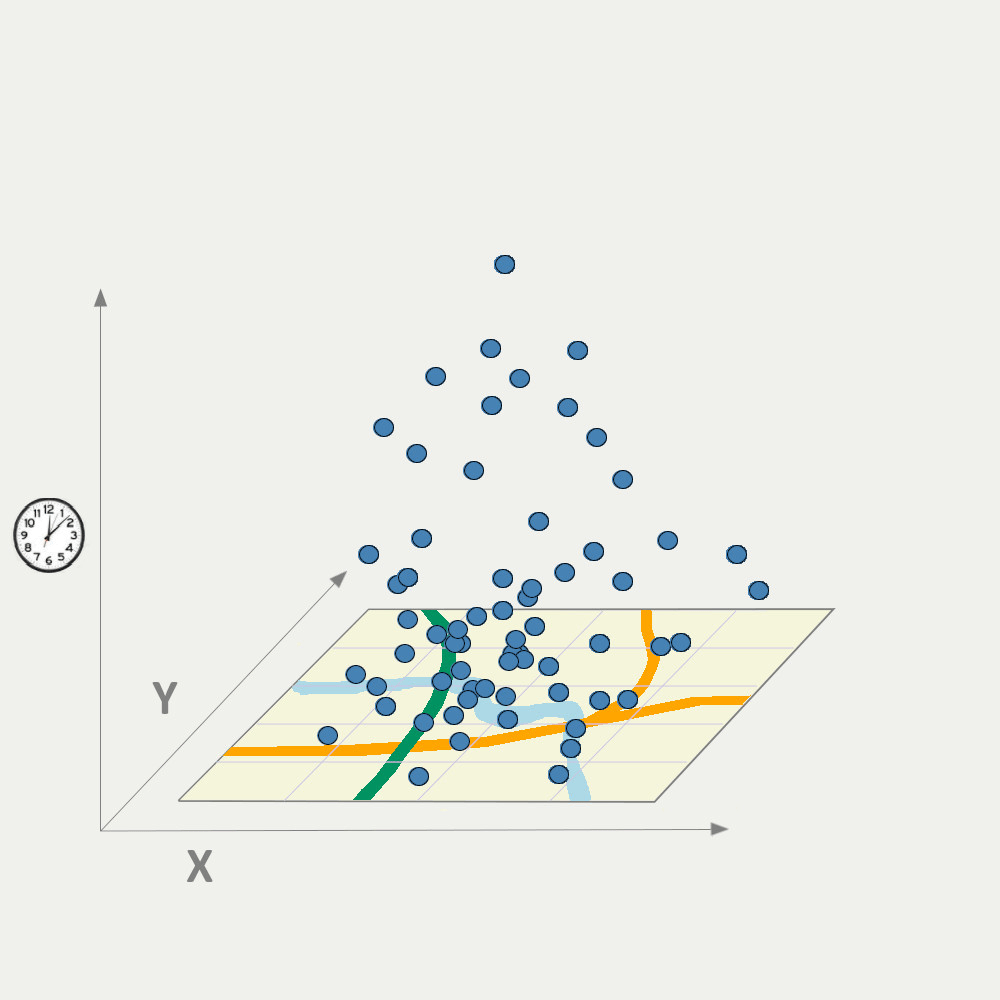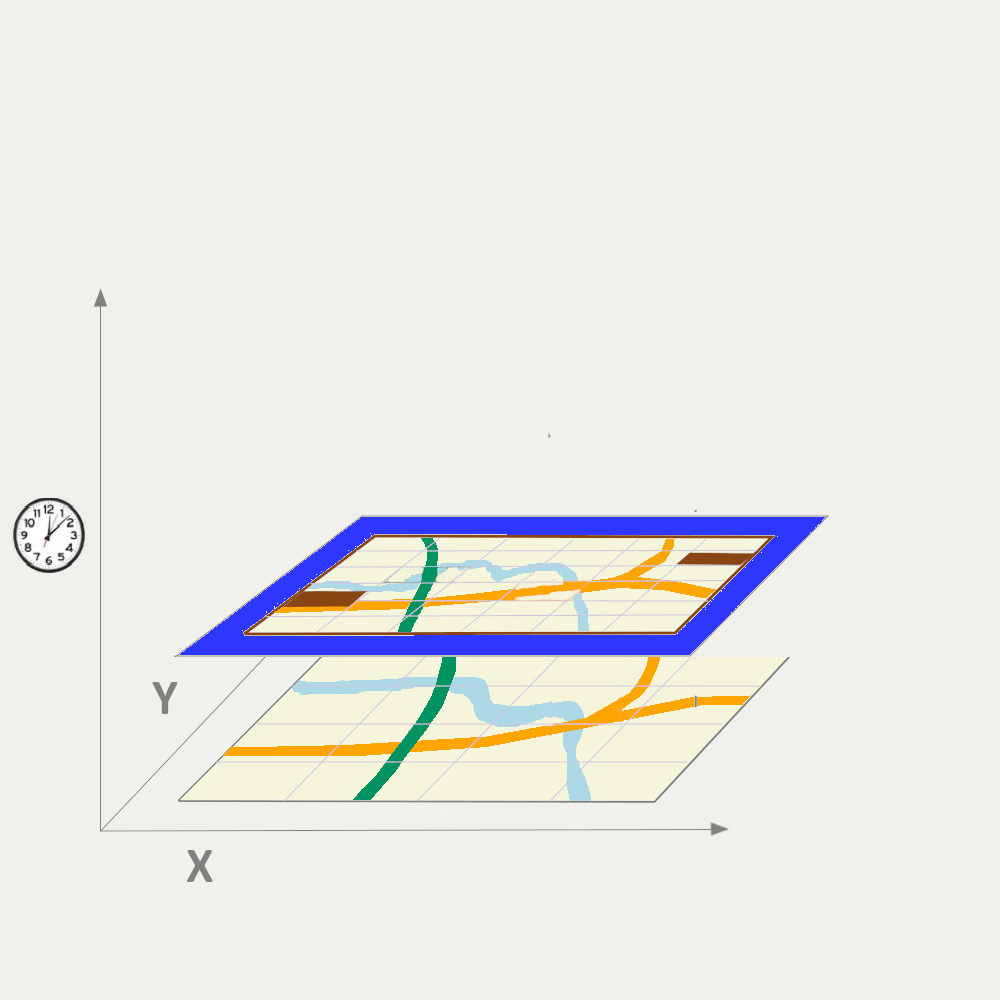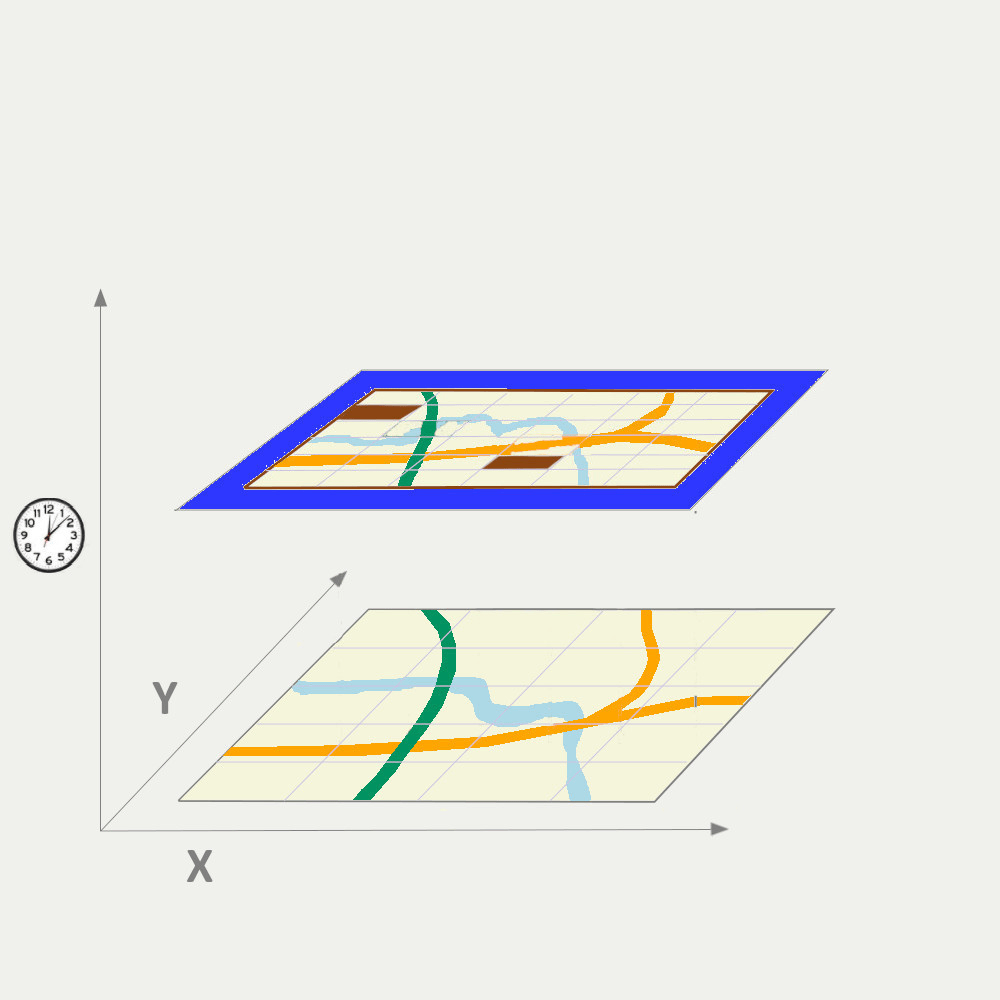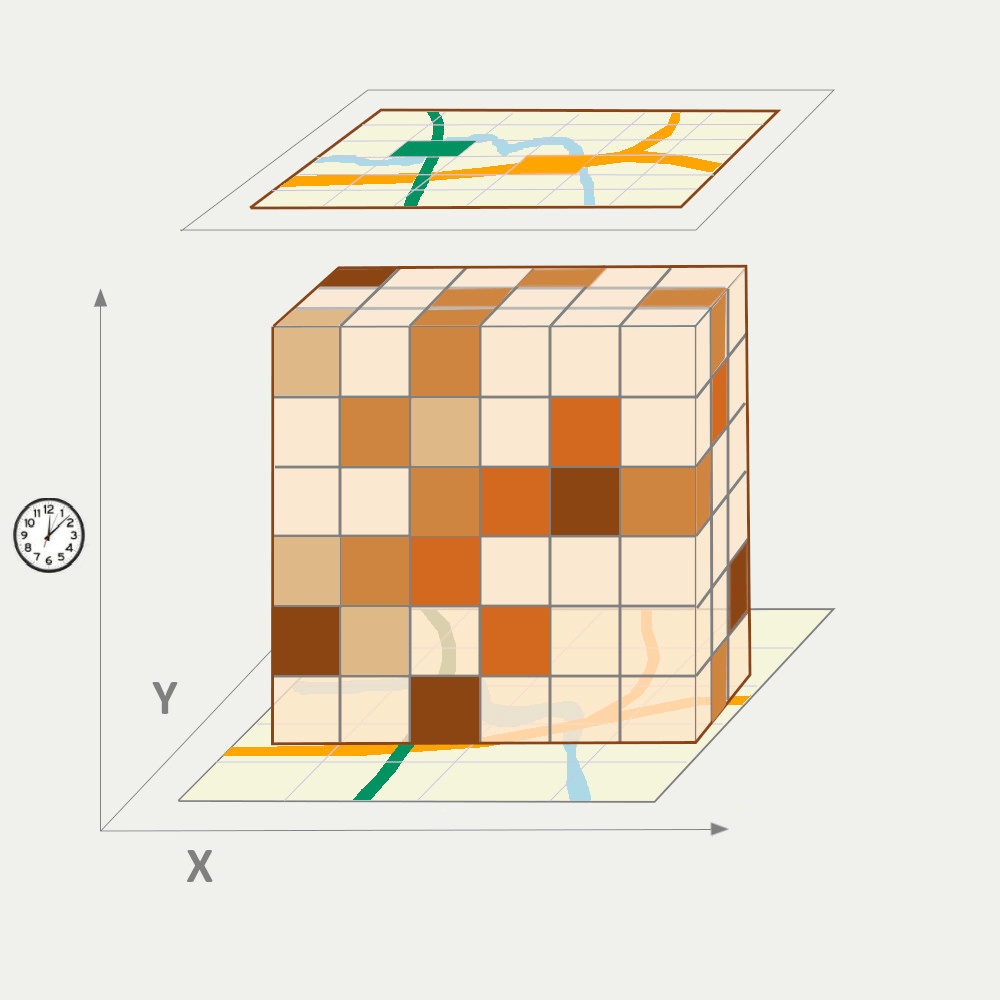
Large-scale, high-resolution mapping of our environment and other spatial processes such as infectious disease, from Geoscientific data of multiple sources (e.g. Earth observations, aerial images, mobile sensors, citizen science), as well as understanding the contributing sources.
General challenges we solve are:
• Data assimilation and information integration:
Integrating geospatial data from diverse sources can overcome the obstacles associated with using data from a single source is used. This requires assimilating data with different supports and from different sources.
• Spatial and spatial-temporal heterogeneity:
Spatial and spatiotemporally varying relationships between predictors and response. When and where the relationship varies may not just be a function of geographical distance but other factors (e.g. the relationship between air pollution concentration and traffic load differs with different fuel, engine types). How could we find the regions within which the relationship alters?
• Spatial and spatiotemporal prediction method optimisation:
A large literature of spatial and spationtemporal prediction methods are developed, but how do we make the best use of them? Do we find a formal workflow to optimise the choosing of the methods with 1) different objectives (e.g. does the optimal method stay the same when making an air pollution map for health study, risk assessment, or urban planning?) and 2) at different spatial and spatiotemporal scales? How can we optimise the model selection and development considering model interpretability, prediction accuracy, uncertainty assessment?
• Model validation and uncertainty quantification:
Mode validation and accuracy assessment is a challenge with nonparametric models and when the data modelling process is complex. Also, there is a conflict between avoiding overlaps between training and test sets, and avoiding model extrapolation. We ask the following questions:
1) What are the strengths and limitations of current uncertainty assessment methods of machine learning models?
2) If we could sample external testing sets, how would we design the sampling scheme? How does the sampling scheme differ when different methods (geostatistics, linear models, tree-based machine learning, deep neural networks) are employed?
3) Could neighbourhood information from predictors contribute to model uncertainty quantification?
 |